讯飞星火大模型“出生已是国内最好”不是自卖自夸,SuperCLUE排行榜来了
· 2023-05-10随着“大模型”时代的到来,全球各大企业都想要趁着人工智能的浪潮分一杯羹。面对市面上层出不穷的AI智能大模型,如何判断其实力成为了难题。据悉,评判一个大型语言模型的好坏通常涉及多个方面。

其中,评估大型语言模型性能的关键指标是可解释性。可解释性是指模型如何解释其预测结果的过程。具有较高可解释性的模型更容易被理解和接受。然而,需要注意的是,每个任务和应用场景都有其特定的需求和优先级,因此在实际评估中可能需要权衡不同的因素。

5月9日,中文通用大模型综合性评测基准SuperCLUE正式发布。它主要回答的问题是:在当前通用大模型大力发展的情况下,中文大模型的效果情况。SuperCLUE主要从三大能力上来评估。首先是基础能力,包括了常见的有代表性的模型能力,如语义理解、对话、逻辑推理、角色模拟、代码、生成与创作等10项能力。其次是专业能力,包括了中学、大学与专业考试,涵盖了从数学、物理、地理到社会科学等50多项能力。最后是中文特性能力,针对有中文特点的任务,包括了中文成语、诗歌、文学、字形等10项多种能力。
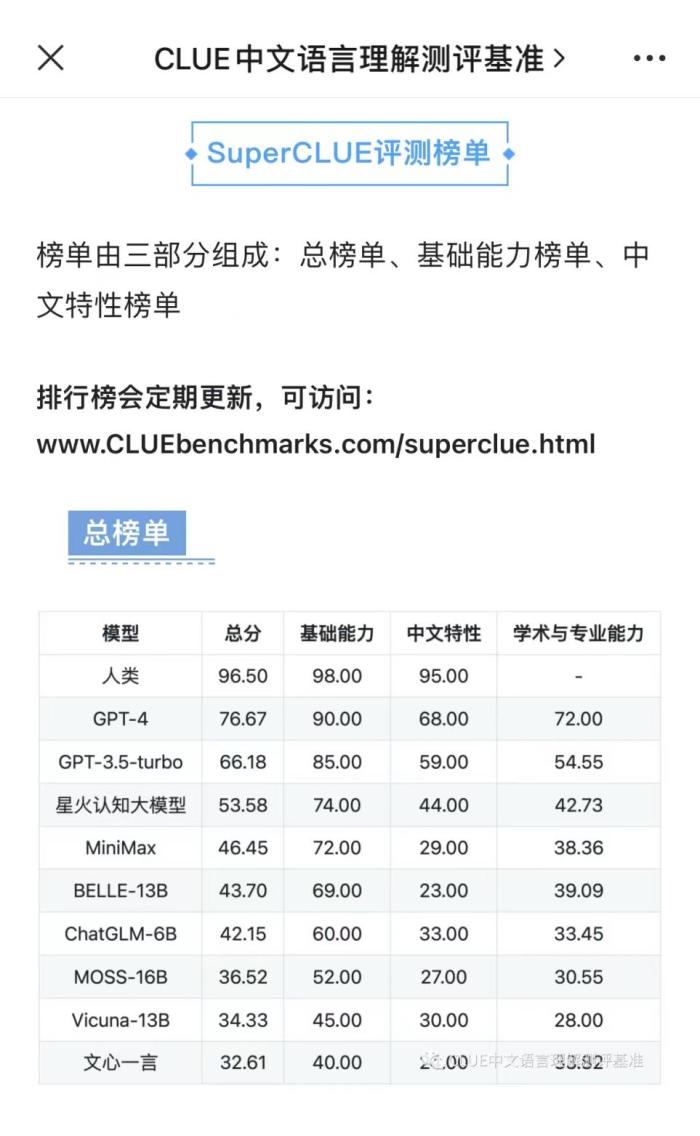
其发布的总榜单显示,GPT-4排名第一,ChatGPT排名第二,星火认知大模型紧随其后排名第三,也充分说明了星火大模型尽管和GPT还有差距,但已经是国产大模型的佼佼者。
科大讯飞在5月6日发布的讯飞星火认知大模型可以说是国内最好!在发布会现场,“真机实测”演示了文本生成、语言理解、知识问答、数学能力等核心能力,星火大模型表现的“很睿智”,不少网友表示感到惊艳、效果超预期。尤其是现场互动环节,网友提问的两个问题:“外星人是否应该戴口罩”、“如何把40平的房子装修出70平的感觉”,星火大模型准确理解、推理,并根据掌握的知识进行解答,现场引发阵阵掌声。
在星火大模型发布会上,科大讯飞董事长刘庆峰也坦言,目前大模型技术还有待攻克的缺陷,比如新知识难以及时更新、事实类问答容易“张冠李戴”,史实、传统典籍等容易“编造情节”等,但这些问题在今年会有明显的改进。

众多周知,大模型背后的核心技术是认知智能。科大讯飞作为人工智能国家队之一,多年来一直深耕认知智能领域,有能力推出自主研发的国产大模型。大模型的核心是算法、数据和算力。算法和数据是科大讯飞的强项,在算力维度上,科大讯飞也联合华为,打造自主可控的算力平台,可以说是国内最有希望实现“智慧涌现”的玩家之一。此外,星火大模型才刚刚发布,现在谈对标ChatGPT也为时过早。科大讯飞能够做到发布前就开放体验,发布会上就现场实测,且落地产品级的行业应用,这份勇气是中国首个,这份实力也是中国首个。
文章推荐:
AdventureX 2026青年黑客松大赛启幕 招商银行赋能AI技术新生代